What is a single page app?
Nick Scialli
November 29, 2021
Sometimes we get so immersed in learning technology that we forget to ask the basic questions. If you started learning front-end software development in the past few years, you were likely quickly introduced to single page application frameworks like React, Vue, and Angular—but their interaction with web servers and how things were in the “before times” may be a bit blurry to you.
Conversely, if you have been a web developer for a while in languages like Java, PHP, or Ruby, you may not have gotten into the single page application world since popular server-side frameworks tend to have excellent templating features.
Regardless of your experience, it’s worth taking stock of how “conventional” web apps work and then how things are different in the single page app world.
In this article, we’ll discuss what a conventional web application is, build a simple app, and then convert it into a single page application.
Conventional web applications
The way web applications used to work was as follows: a user would navigate in their web browser (“the client”) to your website (let’s call it mywebsite.com). This would result in an HTTP GET request over the Internet to a computer somewhere (“the server”).
The server would look at this request and respond with an HTTP response that, among other information, includes some HTML. The client would receive that HTML and render it for the user to view and interact with.
Let’s say that HTML has a link to an “About” page located at mywebsite.com/about. If the user clicks on that link, the browser performs another HTTP GET request. Again, this request is sent over the Internet and received by your server. Your server sees that this is a GET request to the /about route. Based on that information, it sends a new reponse, this time with the HTML associated with the “About” page.
When the client receives the response to this request, the entire screen is replaced with the “About” page HTML. The user can now interact with the “About” page.
This interaction can be represented by the following diagram:

Importantly: for each page our user wants, a new HTTP request is sent over the Internet, a bunch of HTML is returned, and the user’s view is replaced with that HTML.
Building a conventional web application
Let’s build a conventional web application. Our client, as described above, will be whatever web browser you have (Chrome, Firefox, Edge, etc.). We will run our server on our own machine and it will be written in node.js, which is a JavaScript runtime often used to write server applications.
If you don’t have node.js installed on your computer, you can download it for free here.
To start out with, we’ll create a new directory:
mkdir my-websiteNext, we’ll navigate into that directory and initiate a new node project with all of the defaults:
cd my-website
npm init -yNext, we install express, a web application framework for node.
npm install expressWe will now add some HTML files to our server. In the current directory, create the following three files:
index.html
<html>
<head>
<title>Home</title>
</head>
<body>
<main>
<h1>Welcome to my website!</h1>
<p>This is my internet homepage</p>
<h2>Handy links</h2>
</main>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
</body>
</html>about.html
<html>
<head>
<title>About</title>
</head>
<body>
<main>
<h1>About me</h1>
<p>I'm just a person on the internet!</p>
<h2>Handy links</h2>
</main>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
</body>
</html>contact.html
<html>
<head>
<title>Contact</title>
</head>
<body>
<main>
<h1>Contact me</h1>
<p>I can be reached via carrier pigeon</p>
<h2>Handy links</h2>
</main>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
</body>
</html>Great, we now have all our content! Our final task will be to write the server code. Let’s create a file called index.js and put the following code in it:
const express = require('express');
const app = express();
app.get('/', function (_, res) {
res.sendFile(__dirname + '/index.html');
});
app.get('/about', function (_, res) {
res.sendFile(__dirname + '/about.html');
});
app.get('/contact', function (_, res) {
res.sendFile(__dirname + '/contact.html');
});
app.listen(3000, () => {
console.log('Serving the app at http://localhost:3000!');
});If you’re unfamiliar with node/express, this code creates a new express application and then specifices three routes:
- If a
GETrequest arrives for the/route, respond with the contentsindex.html - If a
GETrequest arrives for the/aboutroute, respond with the contentsabout.html - If a
GETrequest arrives for the/contactroute, respond with the contentscontact.html
Let’s take our application for a spin!
In the current directory, run the following command:
node index.jsYou should see the following text:
Serving the app at http://localhost:3000!Using your browser of choice, navigate to http://localhost:3000. You should see the application!
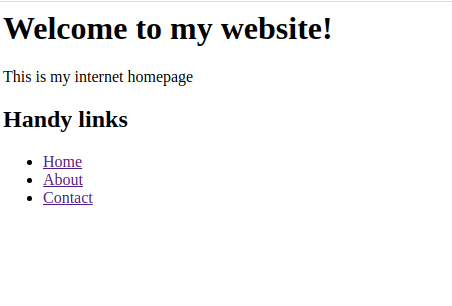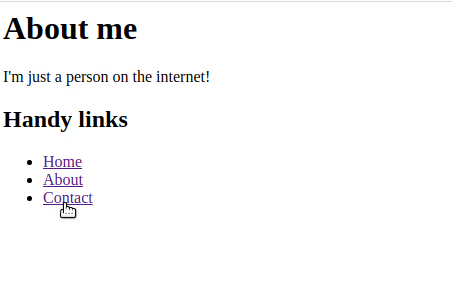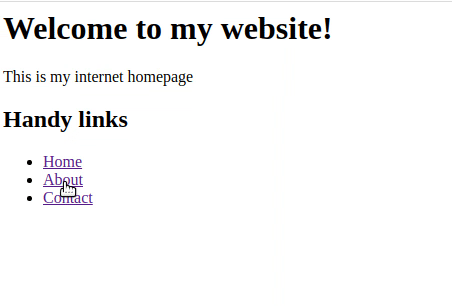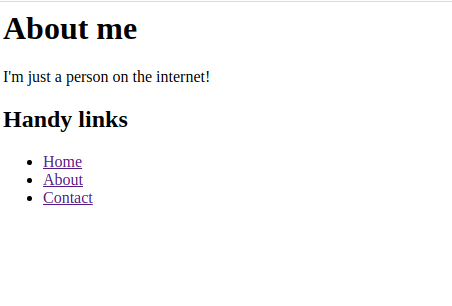
Every time we click a link in the HTML on our client (the browser), an HTTP request is sent to our server, which is running our node/express application. The node/express application interprets the request and sends back some new HTML text. Finally, the clients gets this HTML and displays it to the us.
What is a single page application?
It’s taken a while to get here, but now the payoff. Our “conventional” application can be thought of as a multiple page application: for each link we click in our site, we get an entirely new HTML page back and our screen is totally refreshed.
But what if we didn’t have to contact the server every time we wanted to navigate somewhere in our website? What if the server sends all the necessary information to the client in response to the first request? Maybe we would avoid some page reload time since we wouldn’t have to keep reloading the server.
In other words, what if our client/server flow looked something more like this?

Let’s keep these ideas in mind as we convert out multiple page application to a single page application.
Converting to a single page application
Let’s create a new file and call it spa.html. This fill will start out simple: It’ll have our main element and our navigation:
spa.html
<html>
<head>
<title>Fancy Single Page App</title>
</head>
<body>
<main>This is the single page app</main>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
</body>
</html>We can then rewrite our server code to say “no matter what GET request we receive, respond with this HTML.”
const express = require('express');
const app = express();
app.get('/*', function (_, res) {
res.sendFile(__dirname + '/spa.html');
});
app.listen(3000, () => {
console.log('Serving the app at http://localhost:3000!');
});Now, let’s re-run our server using node index.js and navigate to http://localhost:3000. We sould see our “This is a single page app” text and the site navigation. If we click any of the links, we still send a request to our server, but the server sends back this exact same HTML. It’s a single page!
Of course, this isn’t too interesting yet. Let’s make it so our app starts looking right: we can add some JavaScript inside a <script> tag in our HTML to do the following on page load:
- Look at the current path name (e.g., ”/”, “/about”, “/contact”)
- Set the
innerHTMLof themainelement to the correct content based on the path name - Set the document title based on the path name
spa.html
<html>
<head>
<title>Fancy Single Page App</title>
</head>
<body>
<main>This is the single page app</main>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
<script>
const pages = {
'/': {
title: 'Home',
content: `<h1>Welcome to my website!</h1>
<p>This is my internet homepage</p>
<h2>Handy links</h2>`,
},
'/about': {
title: 'About',
content: `<h1>About me</h1>
<p>I'm just a person on the internet!</p>
<h2>Handy links</h2>`,
},
'/contact': {
title: 'Contact',
content: `<h1>Contact me</h1>
<p>I can be reached via carrier pigeon</p>
<h2>Handy links</h2>`,
},
};
const path = window.location.pathname;
document.querySelector('main').innerHTML = pages[path].content;
document.title = pages[path].title;
</script>
</body>
</html>That seems like a lot! What we’ve done here is stored the title and content for each of our different routes in an object called pages. We then access the current path using window.location.pathname. Finally, we set the main element’s innerHTML property and the document.title property based on the pages object.
The effect looks strikingly similar to our initial app!
But we’re still not quite in single page application territory yet because, in reality, each time we click one of our links we’re sending a request to the server and getting the same response back. We need to prevent our links from performing GET requests and instead manipulate the HTML in our view directly:
<html>
<head>
<title>Fancy Single Page App</title>
</head>
<body>
<main>This is the single page app</main>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/about">About</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
<script>
const pages = {
'/': {
title: 'Home',
content: `<h1>Welcome to my website!</h1>
<p>This is my internet homepage</p>
<h2>Handy links</h2>`,
},
'/about': {
title: 'About',
content: `<h1>About me</h1>
<p>I'm just a person on the internet!</p>
<h2>Handy links</h2>`,
},
'/contact': {
title: 'Contact',
content: `<h1>Contact me</h1>
<p>I can be reached via carrier pigeon</p>
<h2>Handy links</h2>`,
},
};
const path = window.location.pathname;
document.querySelector('main').innerHTML = pages[path].content;
document.title = pages[path].title;
const links = document.querySelectorAll('a');
links.forEach((link) => {
link.addEventListener('click', (e) => {
e.preventDefault();
const path = e.target.pathname;
window.history.pushState({}, pages[path].title, path);
document.querySelector('main').innerHTML = pages[path].content;
document.title = pages[path].title;
});
});
</script>
</body>
</html>This final piece of code adds an event listener to each link in the document. It prevents the default action (i.e., performing the GET request). Instead, it grabs the pathname from the target anchor element, uses window.history.pushState to change the URL right in front of our eyes, and then does the same innerHTML and title changes as our code that executes on load.
Now we can say we have built a basic single page application! If we navigate around the app in our browser, we see it works as expected, but no HTTP requests are being sent to the server.
Is it realistic to send everything to the client immediately?
In reality, we often have some data that can’t be sent to the client immediately. Perhaps we maintain a list of 500,000 books and the user is searching for one. It would be a very bad idea to send 500,000 book titles to the client on initial page load: the bandwidth and load time would be astronomical.
This doesn’t derail our single page application plans, though. It simply means our single page application sometimes needs to make requests from within the client-side JavaScript code. Rather than returning an entire HTML document as a response, our server can just return some data, usually a JSON object, which our single page application can use to populate the document.
Our implementation is hacky
Our implementation is definitely hacky. Any production implementation of a single page application should use a robust library/framework like React, Vue, or Angular. These frameworks all abstract direct document manipulation away from you and implement a lot of other well-tested features.
Drawbacks
Single page applications have their drawbacks. If they get large enough, then you’re potentially sending way too much code to the client at one time and that can result in poor user experience. Because of this issue, features like code splitting have been developed. Code splitting does what it sounds like it does—it splits the front-end code you develop into smaller bundles and sends them to the client only when needed.
State management also gets complicated with single page applications. With multiple page applications, a request is sent the the server, the server does whatever data lookups it needs to do, and then HTML is sent to the client. In single page applications, server requests are happening in the background while users are looking at the HTML document. What do we show the user while these requests are happening? The application has to be in some state. What if there are a few different background requests going at the same time? Do we have one big “loading” indicator or a bunch of smaller indicators? What if one of the three requests fail? Do we show data for the the requests and then a failure indicator for the third?
Conclusion
I hope this article gave you a good pimer on single page applications, conventional applications, or both!


Nick Scialli is a senior UI engineer at Microsoft.